Technical Article
제품 및 Tools
FPGA 이용한 비디오 워터마킹을 위한 OpenCL 애플리케이션 최적화
FPGA 이용한 비디오 워터마킹을 위한 OpenCL 애플리케이션 최적화
2015-10-21
자일링스의SDAccel개발환경은메모리-바운드(Memory-Bound) 문제를해결할수있는최적의방법을제공한다.
비디오 스트리밍 및 다운로드는 컨수머 인터넷 트래픽의 대부분의 차지하고 있으며, 클라우드 컴퓨팅의 견인차가 되고 있다. 지속적으로 증가하고 있는 이러한 형태의 콘텐트에 대한 요구로 인해 특화되지 않은 시스템이나 데이터 센터에서도 비디오 프로세싱 애플리케이션이 확대되고 있다. 이러한 디플로이먼트 패러다임의 변화는 트랜스코딩(Transcoding) 및 워터마킹(Watermarking)과 같은 비디오 콘텐트 준비 및 분배에 따른 각기 다른 연산 집약적 단계의 요구에 부합하도록 신속한 연산 노드 확장이 고려되어야 한다.
우리는 최근에 FPGA 가속 카드를 위한 OpenCLTM로 작성된 비디오 워터마킹 애플리케이션을 컴파일하고 최적화하기 위해 자일링스(Xilinx짋)의 SDAccelTM 개발환경을 이용했다. 비디오 콘텐트 공급업체는 해당 콘텐트를 보호하고 브랜드 표식을 위해 워터마킹을 이용한다.
우리의 목표는 Alpha Data ADM-PCIE-7V3 카드에서 구동하는, 1080p 해상도의 HD(High Definition) 비디오를 30fps(Frames per Second)로 처리할 수 있는 워터마킹 애플리케이션을 디자인하는 것이었다.
SDAccel 개발환경은 디자이너들이 FPGA 구현 툴에 대한 지식이 없어도 OpenCL로 캡처한 애플리케이션을 FPGA에 컴파일할 수 있도록 해준다. 이 비디오 워터마킹 애플리케이션은 SDAccel에서 제공되는 주요 최적화 기법을 도입하는 완벽한 방법을 보여준다.
로고를 삽입한 비디오 워터마킹
비디오 워터마킹 알고리즘의 주요 기능은 비디오 스트림의 특정 위치에 로고를 덮어씌울 수 있다는 것이다. 워터마크에 사용된 로고는 액티브 또는 패시브이다. 액티브 로고는 보통 짧고 반복적인 비디오 클립으로 묘사되는 반면, 패시브 로고는 스틸 이미지다.
브로드캐스팅 업체들 사이에서 가장 보편적으로 사용되는 기법은 비디오 스트림에 패시브 워터마크처럼 회사 로고를 각인하는 방법을 사용하고 있으며, 이는 우리 디자인 예시의 목표이기도 하다. 애플리케이션은 아래 공식 연산에 기반하여 픽셀 x 픽셀 레벨 단위로 패시브 로고를 삽입한다.
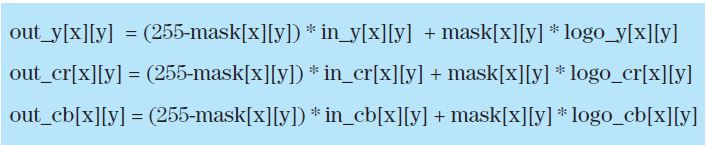
입력 및 출력 프레임은 2-차원 어레이로, YCbCr 컬러 공간을 이용해 픽셀을 표현한다. 이 컬러 공간에서 각 픽셀은 3개의 구성요소로 묘사되는데, Y는 광도(Luma) 요소이고, Cb는 청색 차이에 다른 채도, Cr은 적색 차이에 따른 채도 요소이다. 각 구성요소는 8bit 값으로 나타내며, 픽셀 당 총 24bit가 된다.
로고는 삽입될 콘텐트를 포함하고 있는 2차원 이미지다. 마스크 또한 이미지이지만, 로고의 윤곽만 포함하고 있다. 마스크의 픽셀은 백색 또는 흑색이다. 마스크의 백색 픽셀은 로고의 삽입 위치를 나타내며, 흑색 픽셀은 훼손되지 않은 본래 그대로의 픽셀을 나타낸다. 그림 1은 비디오 워터마킹 알고리즘의 동작 사례를 보여준다.

타깃 시스템 및 초기 구현
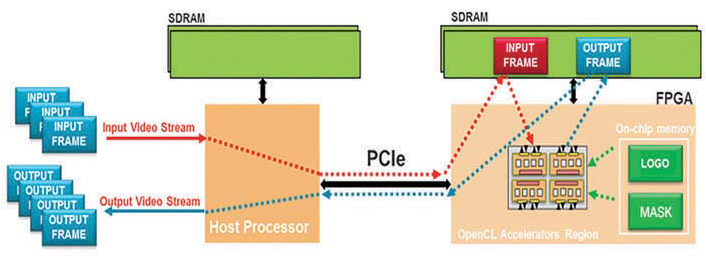
우리가 애플리케이션을 실행하고자 하는 시스템은 그림 2에 나타내었다. 이는 PCIe짋 링크로 x86 프로세서와 통신하는 Alpha Data ADMPCIE-7V3 카드로 구성되어 있다. 이 시스템에서 호스트 프로세서는 디스크에서 입력 비디오 스트림을 검색하여 디바이스의 글로벌 메모리로 전송한다. 디바이스 글로벌 메모리는 FPGA에서 직접 액세스할 수 있는 FPGA 카드 상의 메모리이다. 디바이스 글로벌 메모리에 비디오 프레임을 배치하는 것과 더불어, 로고 및 마스크는 호스트에서 가속 카드로 전송되며, 저지연 BRAM 메모리를 활용하기 위해 온칩 메모리에 배치된다. 이 애플리케이션은 패시브 로고를 사용하기 때문에 스틸 이미지를 위한 데이터와 배치 위치만 온칩 메모리에 저장하면 된다.
데이터가 설정되고 나면, 호스트 프로세서는 시작 신호를 FPGA 패브릭 상의 워터마킹 커널에 보낸다. 이 신호는 3가지 일을 수행하도록 커널을 트리거한다. 먼저 디바이스 글로벌 메모리에서 입력 비디오 프레임을 불러오고, 마스크에서 정의된 위치에 로고를 삽입하고, 처리된 프레임을 프로세서가 불러오도록 다시 디바이스 글로벌 메모리에 배치한다.
비디오 스트림의 모든 프레임에 대한 연산 및 데이터 전송 조정은 그림 3처럼 코드를 통해 달성된다.

호스트 프로세서에서 실행되는 이 코드는 비디오 프레임을 FPGA 가속 카드로 전송하고, 가속기를 구동시킨 다음, FPGA 가속 카드에서 처리된 프레임을 회수하는 역할을 맡는다.
FPGA에 최초로 구현된 워터마킹 알고리즘은 그림 4에 나타내었다. 이는 기능적으로는 정확하게 애플리케이션을 구현한 것이지만, 어떠한 성능 최적화나 FPGA 패브릭의 기능을 고려한 것은 아니다. 이 코드를 SDAccel에서 컴파일한다면, 최대 0.5fps 처리량으로 Alpha Data 카드를 구동시킬 수 있다.
그림 4의 코드에서 확인할 수 있듯이, 워터마킹 알고리즘은 연산 집약적 디자인은 아니다. 대부분의 시간은 비디오 프레임을 읽고, 쓰기 위해 메모리에 액세스하는데 소모된다. 따라서 이번 디자인 사례를 최적화하기 위해서는 메모리 대역폭에 주력해야 한다.

벡터화를 이용한 메모리 액세스 최적화
다른 소프트웨어-프로그래머블 패브릭과 비교해 FPGA 패브릭의 장점 중 하나는 유연성 및 메모리와의 인터커넥트 버스 컨피규레이션이다. SDAccel은 애플리케이션 커널에 기반한 메모리 아키텍처와 커스텀-사이즈의 데이터 경로를 생성한다. 커널의 더 높은 메모리 대역폭은 한번에 다중 픽셀을 처리하도록 코드를 수정함으로써 추론이 가능하며, 이 절차를 벡터화라고 부른다.
벡터화 레벨은 애플리케이션이나 사용되는 FPGA 가속 카드에 따라 다르다. Alpha Data 카드의 경우, 디바이스 글로벌 메모리와의 인터페이스는 512bit 폭을 가지고 있으며, 이는 SDAccel에서 커널이 이용 가능한 최대 AXI 인터커넥트 폭과 부합한다. 정해진 512bit 바운드리로 이 애플리케이션은 한번에 20픽셀을 처리하도록 수정된다(24bits/pixel x 20pixels = 504 bits). SDAccel은 모든 종류의 벡터 데이터를 지원한다. 따라서 이 애플리케이션을 위한 코드의 벡터화는 그림 5에 나타낸 것처럼, char20으로 모든 어레이의 데이터 타입을 변경하는 것만큼 간단하며, 처리량은 12fps를 달성했다.

버스트를 이용한 메모리 액세스 최적화
벡터화를 통해 애플리케이션 성능을 상당히 개선할 수 있었지만, 목표치인 30fps에 도달하기에는 충분하지 않다. 이 애플리케이션은 커널이 한번에 20픽셀 만을 메모리에 전송하기 때문에 여전히 메모리 바운드(Memory Bound)가 남아 있다. 애플리케이션 상의 메모리 제약에 따른 영향을 줄이기 위해, 20픽셀 보다 큰 데이터 세트에 맞도록 메모리에 버스트 읽기/쓰기 동작을 생성하기 위해 커널 코드를 수정해야만 했다. 수정된 커널 코드는 그림 6에 나타냈다.

커널 코드에 대한 최초의 수정은 한번에 하나의 픽셀 블록을 저장하도록 커널의 온칩 스토리지를 정의하는 것이었다. 온칩 메모리는 커널 코드에 표기된 어레이로 정의되었다. 메모리의 버스트 처리과정을 시작하기 위해, 이 코드는 DDR에서 커널 내부의 BRAM 스토리지로 데이터 블록을 이동하도록 memcpy 명령어를 초기화했다. 온칩 메모리 리소스 크기 및 처리될 데이터 양에 기반해, 비디오 프레임은 그림 7과 같이 1920 x 54픽셀 기준 20개 블록으로 나뉘어졌다.

memcpy 동작으로 커널 내 블록으로 데이터를 배치하고 나면, 알고리즘은 데이터 블록 상의 워터마킹 알고리즘을 실행하고, 결과를 다시 커널 어레이에 배치한다. 블록 프로세싱 결과는 memcpy 동작을 이용해 DDR 메모리로 다시 전송된다. 이러한 동작 시퀀스는 해당 프레임의 모든 블록이 처리될 때까지 20번 반복된다. 커널 코드에 대한 수정 결과, 시스템 성능은 38fps에 달했으며, 원래 목표인 30fps를 초과했다.
폭 넒은 활용성
이번처럼 애플리케이션 구현에 필요한 최적화는 SDAccel을 이용한 소프트웨어 최적화이다. 따라서 이러한 최적화는 GPU와 같은 다른 프로세싱 패브릭에서 성능을 추출하는 것과 유사하다. SDAccel을 이용한 결과처럼, 작업, 드라이버, IP 배치 및 인터커넥트에 PCIe 링크를 적용하는 세부항목들은 문제가 되지 않으며, 디자이너들은 오로지 타깃 애플리케이션에만 전념할 수 있게 된다.
워터마킹 애플리케이션에서 구현한 최적화는 SDAccel을 이용해 컴파일한 모든 디자인에도 적용 가능하다. 실제로 비디오 워터마킹은 자일링스가 SDAccel에서 제공하는 최적화 방법들을 가장 잘 보여주는 사례이다.
글/ 야스미나바실예비치(JasminaVasiljevic), 토론토대학연구원
페르난도마르티네스발리나(Fernando Martinez Vallina) 박사, 자일링스소프트웨어개발매니저
페르난도마르티네스발리나(Fernando Martinez Vallina) 박사, 자일링스소프트웨어개발매니저
비디오 스트리밍 및 다운로드는 컨수머 인터넷 트래픽의 대부분의 차지하고 있으며, 클라우드 컴퓨팅의 견인차가 되고 있다. 지속적으로 증가하고 있는 이러한 형태의 콘텐트에 대한 요구로 인해 특화되지 않은 시스템이나 데이터 센터에서도 비디오 프로세싱 애플리케이션이 확대되고 있다. 이러한 디플로이먼트 패러다임의 변화는 트랜스코딩(Transcoding) 및 워터마킹(Watermarking)과 같은 비디오 콘텐트 준비 및 분배에 따른 각기 다른 연산 집약적 단계의 요구에 부합하도록 신속한 연산 노드 확장이 고려되어야 한다.
우리는 최근에 FPGA 가속 카드를 위한 OpenCLTM로 작성된 비디오 워터마킹 애플리케이션을 컴파일하고 최적화하기 위해 자일링스(Xilinx짋)의 SDAccelTM 개발환경을 이용했다. 비디오 콘텐트 공급업체는 해당 콘텐트를 보호하고 브랜드 표식을 위해 워터마킹을 이용한다.
우리의 목표는 Alpha Data ADM-PCIE-7V3 카드에서 구동하는, 1080p 해상도의 HD(High Definition) 비디오를 30fps(Frames per Second)로 처리할 수 있는 워터마킹 애플리케이션을 디자인하는 것이었다.
SDAccel 개발환경은 디자이너들이 FPGA 구현 툴에 대한 지식이 없어도 OpenCL로 캡처한 애플리케이션을 FPGA에 컴파일할 수 있도록 해준다. 이 비디오 워터마킹 애플리케이션은 SDAccel에서 제공되는 주요 최적화 기법을 도입하는 완벽한 방법을 보여준다.
로고를 삽입한 비디오 워터마킹
비디오 워터마킹 알고리즘의 주요 기능은 비디오 스트림의 특정 위치에 로고를 덮어씌울 수 있다는 것이다. 워터마크에 사용된 로고는 액티브 또는 패시브이다. 액티브 로고는 보통 짧고 반복적인 비디오 클립으로 묘사되는 반면, 패시브 로고는 스틸 이미지다.
브로드캐스팅 업체들 사이에서 가장 보편적으로 사용되는 기법은 비디오 스트림에 패시브 워터마크처럼 회사 로고를 각인하는 방법을 사용하고 있으며, 이는 우리 디자인 예시의 목표이기도 하다. 애플리케이션은 아래 공식 연산에 기반하여 픽셀 x 픽셀 레벨 단위로 패시브 로고를 삽입한다.
입력 및 출력 프레임은 2-차원 어레이로, YCbCr 컬러 공간을 이용해 픽셀을 표현한다. 이 컬러 공간에서 각 픽셀은 3개의 구성요소로 묘사되는데, Y는 광도(Luma) 요소이고, Cb는 청색 차이에 다른 채도, Cr은 적색 차이에 따른 채도 요소이다. 각 구성요소는 8bit 값으로 나타내며, 픽셀 당 총 24bit가 된다.
로고는 삽입될 콘텐트를 포함하고 있는 2차원 이미지다. 마스크 또한 이미지이지만, 로고의 윤곽만 포함하고 있다. 마스크의 픽셀은 백색 또는 흑색이다. 마스크의 백색 픽셀은 로고의 삽입 위치를 나타내며, 흑색 픽셀은 훼손되지 않은 본래 그대로의 픽셀을 나타낸다. 그림 1은 비디오 워터마킹 알고리즘의 동작 사례를 보여준다.
타깃 시스템 및 초기 구현
우리가 애플리케이션을 실행하고자 하는 시스템은 그림 2에 나타내었다. 이는 PCIe짋 링크로 x86 프로세서와 통신하는 Alpha Data ADMPCIE-7V3 카드로 구성되어 있다. 이 시스템에서 호스트 프로세서는 디스크에서 입력 비디오 스트림을 검색하여 디바이스의 글로벌 메모리로 전송한다. 디바이스 글로벌 메모리는 FPGA에서 직접 액세스할 수 있는 FPGA 카드 상의 메모리이다. 디바이스 글로벌 메모리에 비디오 프레임을 배치하는 것과 더불어, 로고 및 마스크는 호스트에서 가속 카드로 전송되며, 저지연 BRAM 메모리를 활용하기 위해 온칩 메모리에 배치된다. 이 애플리케이션은 패시브 로고를 사용하기 때문에 스틸 이미지를 위한 데이터와 배치 위치만 온칩 메모리에 저장하면 된다.
데이터가 설정되고 나면, 호스트 프로세서는 시작 신호를 FPGA 패브릭 상의 워터마킹 커널에 보낸다. 이 신호는 3가지 일을 수행하도록 커널을 트리거한다. 먼저 디바이스 글로벌 메모리에서 입력 비디오 프레임을 불러오고, 마스크에서 정의된 위치에 로고를 삽입하고, 처리된 프레임을 프로세서가 불러오도록 다시 디바이스 글로벌 메모리에 배치한다.
비디오 스트림의 모든 프레임에 대한 연산 및 데이터 전송 조정은 그림 3처럼 코드를 통해 달성된다.
호스트 프로세서에서 실행되는 이 코드는 비디오 프레임을 FPGA 가속 카드로 전송하고, 가속기를 구동시킨 다음, FPGA 가속 카드에서 처리된 프레임을 회수하는 역할을 맡는다.
FPGA에 최초로 구현된 워터마킹 알고리즘은 그림 4에 나타내었다. 이는 기능적으로는 정확하게 애플리케이션을 구현한 것이지만, 어떠한 성능 최적화나 FPGA 패브릭의 기능을 고려한 것은 아니다. 이 코드를 SDAccel에서 컴파일한다면, 최대 0.5fps 처리량으로 Alpha Data 카드를 구동시킬 수 있다.
그림 4의 코드에서 확인할 수 있듯이, 워터마킹 알고리즘은 연산 집약적 디자인은 아니다. 대부분의 시간은 비디오 프레임을 읽고, 쓰기 위해 메모리에 액세스하는데 소모된다. 따라서 이번 디자인 사례를 최적화하기 위해서는 메모리 대역폭에 주력해야 한다.
벡터화를 이용한 메모리 액세스 최적화
다른 소프트웨어-프로그래머블 패브릭과 비교해 FPGA 패브릭의 장점 중 하나는 유연성 및 메모리와의 인터커넥트 버스 컨피규레이션이다. SDAccel은 애플리케이션 커널에 기반한 메모리 아키텍처와 커스텀-사이즈의 데이터 경로를 생성한다. 커널의 더 높은 메모리 대역폭은 한번에 다중 픽셀을 처리하도록 코드를 수정함으로써 추론이 가능하며, 이 절차를 벡터화라고 부른다.
벡터화 레벨은 애플리케이션이나 사용되는 FPGA 가속 카드에 따라 다르다. Alpha Data 카드의 경우, 디바이스 글로벌 메모리와의 인터페이스는 512bit 폭을 가지고 있으며, 이는 SDAccel에서 커널이 이용 가능한 최대 AXI 인터커넥트 폭과 부합한다. 정해진 512bit 바운드리로 이 애플리케이션은 한번에 20픽셀을 처리하도록 수정된다(24bits/pixel x 20pixels = 504 bits). SDAccel은 모든 종류의 벡터 데이터를 지원한다. 따라서 이 애플리케이션을 위한 코드의 벡터화는 그림 5에 나타낸 것처럼, char20으로 모든 어레이의 데이터 타입을 변경하는 것만큼 간단하며, 처리량은 12fps를 달성했다.
버스트를 이용한 메모리 액세스 최적화
벡터화를 통해 애플리케이션 성능을 상당히 개선할 수 있었지만, 목표치인 30fps에 도달하기에는 충분하지 않다. 이 애플리케이션은 커널이 한번에 20픽셀 만을 메모리에 전송하기 때문에 여전히 메모리 바운드(Memory Bound)가 남아 있다. 애플리케이션 상의 메모리 제약에 따른 영향을 줄이기 위해, 20픽셀 보다 큰 데이터 세트에 맞도록 메모리에 버스트 읽기/쓰기 동작을 생성하기 위해 커널 코드를 수정해야만 했다. 수정된 커널 코드는 그림 6에 나타냈다.
커널 코드에 대한 최초의 수정은 한번에 하나의 픽셀 블록을 저장하도록 커널의 온칩 스토리지를 정의하는 것이었다. 온칩 메모리는 커널 코드에 표기된 어레이로 정의되었다. 메모리의 버스트 처리과정을 시작하기 위해, 이 코드는 DDR에서 커널 내부의 BRAM 스토리지로 데이터 블록을 이동하도록 memcpy 명령어를 초기화했다. 온칩 메모리 리소스 크기 및 처리될 데이터 양에 기반해, 비디오 프레임은 그림 7과 같이 1920 x 54픽셀 기준 20개 블록으로 나뉘어졌다.
memcpy 동작으로 커널 내 블록으로 데이터를 배치하고 나면, 알고리즘은 데이터 블록 상의 워터마킹 알고리즘을 실행하고, 결과를 다시 커널 어레이에 배치한다. 블록 프로세싱 결과는 memcpy 동작을 이용해 DDR 메모리로 다시 전송된다. 이러한 동작 시퀀스는 해당 프레임의 모든 블록이 처리될 때까지 20번 반복된다. 커널 코드에 대한 수정 결과, 시스템 성능은 38fps에 달했으며, 원래 목표인 30fps를 초과했다.
폭 넒은 활용성
이번처럼 애플리케이션 구현에 필요한 최적화는 SDAccel을 이용한 소프트웨어 최적화이다. 따라서 이러한 최적화는 GPU와 같은 다른 프로세싱 패브릭에서 성능을 추출하는 것과 유사하다. SDAccel을 이용한 결과처럼, 작업, 드라이버, IP 배치 및 인터커넥트에 PCIe 링크를 적용하는 세부항목들은 문제가 되지 않으며, 디자이너들은 오로지 타깃 애플리케이션에만 전념할 수 있게 된다.
워터마킹 애플리케이션에서 구현한 최적화는 SDAccel을 이용해 컴파일한 모든 디자인에도 적용 가능하다. 실제로 비디오 워터마킹은 자일링스가 SDAccel에서 제공하는 최적화 방법들을 가장 잘 보여주는 사례이다.
- 적용분야 :
- Data Center
- 관련제품 :
- SDAccel